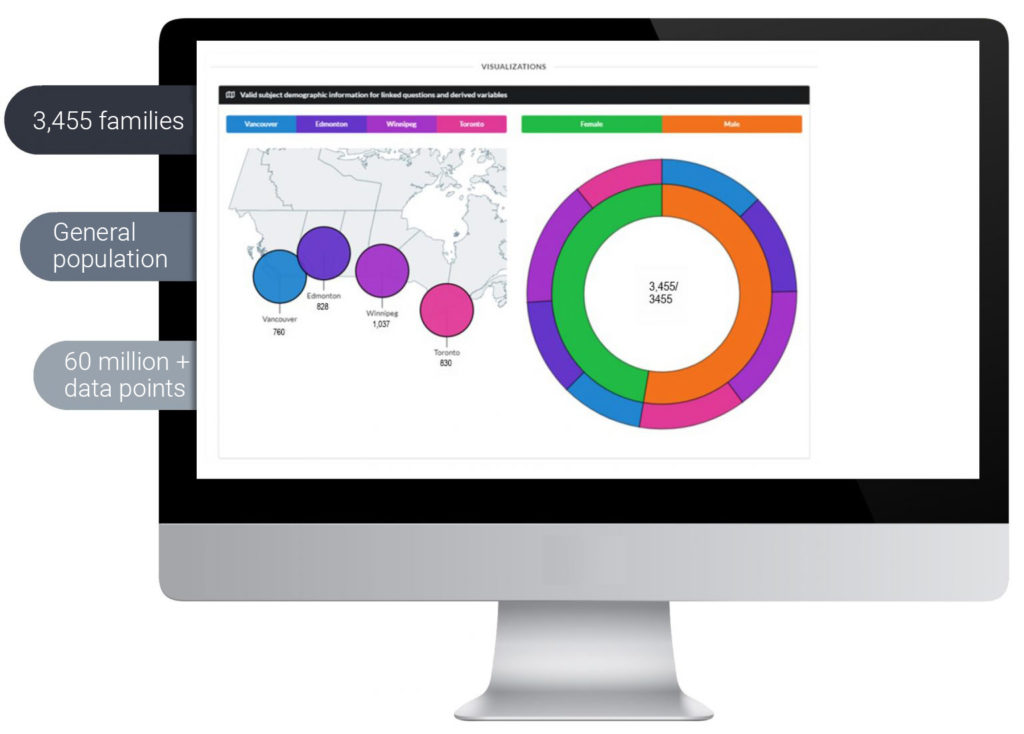
“Big data” and a systems biology platform
CHILD data
Detailed environmental and health questionnaires have been completed by CHILD Study subjects at 13 different time points from mid-pregnancy to 8 years, with more coming at age 12 and beyond. No similar study has analyzed the home environment of such a large pregnancy-based cohort at the same level of detail, with “environment” interpreted broadly to include physical, chemical, viral, bacterial, nutritional and psychosocial exposures.
Other data collected by questionnaires include: mode of delivery; duration and exclusivity of breastfeeding; use of daycare; exposures to medications, especially antibiotics; maternal diet during pregnancy; and infant/child diet and growth.
See the list of questionnaires used from pregnancy to age 12 years.
Access questionnaires (password protected)Clinical measures taken include general anthropometrics, allergy skin prick tests, blood pressure, waist circumference, skinfold thickness and lung function (spirometry).
The data increasingly being generated by analysis of the Study’s biological samples, including through genetic and epigenetic studies, are retained by the Study and integrated into its bioinformatics platform.
Parents have provided permission to access appropriate databases, including routine health and social records, for supplemental information.
Key variables obtained by questionnaire
| Current residence |
| Previous residences (12mo) |
| Changes of residence |
| Type and age of home |
| Characteristics of home |
| Building materials |
| Garage characteristics |
| Heating/Cooling systems |
| Moisture and ventilation |
| Basement/crawl space |
| Water leaks and mold |
| Swimming pool, hot tub, sauna |
| Home improvements |
| Furniture |
| Cooking systems |
| Cleaning habits |
| Chemicals used/stored in home |
| Smoking in/near the home |
| Characteristics of bedroom |
| Occupancy (# people in home) |
| Pets in home |
| Insects and pests in home |
| Neighbourhood characteristics |
| Child bedroom dust |
| Most-used living area dust |
| Furry Pets in home |
| Child bedroom dust |
| Most-used living area dust |
| NO2 exposure |
| Annual average temperature |
| Normalized difference vegetation index (NDVI) |
| Annual average ozone |
| Annual average PM2.5 |
| Annual average SO2 |
| Maternal demographics |
| Health/medical conditions (prenatal, during pregnancy, postpartum) |
| Maternal medications |
| Maternal smoking prior to/during pregnancy |
| Maternal respiratory syumptoms |
| Maternal diagnosed asthma |
| Maternal allergies |
| Maternal occupation |
| Family structure |
| Health of other children |
| Health during pregnancy |
| Diet before and during pregnancy (FFQ) |
| Vitamins and supplements |
| Breastfeeding |
| Pre/Postnatal maternal stress |
| Socioeconomic status |
| Depression |
| Labour and delivery |
| Post-partum stress |
| Parenting stress |
| Hobbies and activities in home |
| Parenting behaviour |
| Physical activity |
| Body composition |
| Blood pressure |
| Lung function (spirometry) |
| Height/weight |
| Allergy skin testing |
| Columbia Impairment Scale for child |
| Family eating habits/patterns |
| Tobacco/vaping/cannabis use and exposure |
| Smoking in/near the home |
| Maternal medications |
| Maternal smoking prior to/during pregnancy |
| Maternal diagnosed asthma |
| Maternal allergies |
| Diet during pregnancy (FFQ) |
| Maternal Depression |
| Maternal Allergy skin testing |
| Paternal demographics |
| Paternal health/medical conditions |
| Paternal medications |
| Paternal smoking prior to/during pregnancy |
| Paternal respiratory symptoms |
| Paternal diagnosed asthma |
| Paternal allergies |
| Paternal occupation |
| Family structure |
| Hobbies and activities in home |
| Parenting behaviour |
| Physical activity |
| Body composition |
| Blood pressure |
| Lung function (spirometry) |
| Height/weight |
| Allergy skin testing |
| Family eating habits/patterns |
| Tobacco/vaping/cannabis use and exposure |
| Paternal demographics |
| Paternal diagnosed asthma |
| Paternal allergies |
| Paternal Allergy skin testing |
| Mode of delivery |
| Child health/medical conditions |
| Medications around birth |
| Sleeping arrangements |
| Activities outside home |
| Colds and infections |
| Coughing episodes |
| Wheezing episodes |
| Medications |
| Vitamins and supplements |
| Food allergy |
| Atopic dermatitis/eczema/rhinitis |
| Doctor visits |
| Hospital/ER visits |
| Breastfeeding |
| Introduction of milk, solids |
| Diet (FFQ) |
| Vaccinations |
| Time/activity/locations |
| Travel times/modes/exposures |
| Sleep habits, behaviour, sleepiness |
| Screen time and sedentary behaviour |
| Activity levels |
| Behaviour |
| Daycare arrangements |
| School characteristics/location/class composition |
| Farm animal exposure |
| Physical activity |
| Height/weight |
| Skin folds |
| Head/Arm/Waist circumference |
| Body composition |
| Lung function (spirometry) |
| Asthma diagnosis (methacholine challenge) |
| Allergy skin testing |
| Blood pressure |
| Accelerometry/GPS (7 days) |
| Childhood Asthma Control Test |
| Body image (self-identified) |
| Gender (self-identified) |
| Puberty staging |
| Privacy |
| Anxiety (self-identified) |
| Columbia Impairment Scale (self-identified) |
| Bullying (self-identified) |
| Depression (self-identified) |
| School Performance |
| Eating habits/patterns |
| Smoke exposure |
| Child health/medical conditions |
| Medications around birth |
| Coughing episodes |
| Wheeze |
| Medications |
| Allergy skin testing |
| Atopic dermatitis/eczema/rhinitis |
| Antibiotics in first year of life |
| Introduction of milk and solids |
| Weight for age trajectories birth to 5 years |
| Lung function (spirometry) |
| Asthma diagnosis (methacholine challenge) |
| Food allergy |
| Breastfeeding |
Current residence |
Previous residences (12mo) |
Changes of residence |
Type and age of home |
Characteristics of home |
Building materials |
Garage characteristics |
Heating/Cooling systems |
Moisture and ventilation |
Basement/crawl space |
Water leaks and mold |
Swimming pool, hot tub, sauna |
Home improvements |
Furniture |
Cooking systems |
Cleaning habits |
Chemicals used/stored in home |
Smoking in/near the home |
Characteristics of bedroom |
Occupancy (# people in home) |
Pets in home |
Insects and pests in home |
Neighbourhood characteristics |
Child bedroom dust |
Most-used living area dust |
Maternal demographics |
Health/medical conditions (prenatal, during pregnancy, postpartum) |
Maternal medications |
Maternal smoking prior to/during pregnancy |
Maternal respiratory syumptoms |
Maternal diagnosed asthma |
Maternal allergies |
Maternal occupation |
Family structure |
Health of other children |
Health during pregnancy |
Diet before and during pregnancy (FFQ) |
Vitamins and supplements |
Breastfeeding |
Pre/Postnatal maternal stress |
Socioeconomic status |
Depression |
Labour and delivery |
Post-partum stress |
Parenting stress |
Hobbies and activities in home |
Parenting behaviour |
Physical activity |
Body composition |
Blood pressure |
Lung function (spirometry) |
Height/weight |
Allergy skin testing |
Columbia Impairment Scale for child |
Family eating habits/patterns |
Tobacco/vaping/cannabis use and exposure |
Furry Pets in home |
Child bedroom dust |
Most-used living area dust |
NO2 exposure |
Annual average temperature |
Normalized difference vegetation index (NDVI) |
Annual average ozone |
Annual average PM2.5 |
Annual average SO2 |
Smoking in/near the home |
Maternal medications |
Maternal smoking prior to/during pregnancy |
Maternal diagnosed asthma |
Maternal allergies |
Diet during pregnancy (FFQ) |
Maternal Depression |
Maternal Allergy skin testing |
Paternal demographics |
Paternal health/medical conditions |
Paternal medications |
Paternal smoking prior to/during pregnancy |
Paternal respiratory symptoms |
Paternal diagnosed asthma |
Paternal allergies |
Paternal occupation |
Family structure |
Hobbies and activities in home |
Parenting behaviour |
Physical activity |
Body composition |
Blood pressure |
Lung function (spirometry) |
Height/weight |
Allergy skin testing |
Family eating habits/patterns |
Tobacco/vaping/cannabis use and exposure |
Paternal demographics |
Paternal diagnosed asthma |
Paternal allergies |
Paternal Allergy skin testing |
Mode of delivery |
Child health/medical conditions |
Medications around birth |
Sleeping arrangements |
Activities outside home |
Colds and infections |
Coughing episodes |
Wheezing episodes |
Medications |
Vitamins and supplements |
Food allergy |
Atopic dermatitis/eczema/rhinitis |
Doctor visits |
Hospital/ER visits |
Breastfeeding |
Introduction of milk, solids |
Diet (FFQ) |
Vaccinations |
Time/activity/locations |
Travel times/modes/exposures |
Sleep habits, behaviour, sleepiness |
Screen time and sedentary behaviour |
Activity levels |
Behaviour |
Daycare arrangements |
School characteristics/location/class composition |
Farm animal exposure |
Physical activity |
Height/weight |
Skin folds |
Head/Arm/Waist circumference |
Body composition |
Lung function (spirometry) |
Asthma diagnosis (methacholine challenge) |
Allergy skin testing |
Blood pressure |
Accelerometry/GPS (7 days) |
Childhood Asthma Control Test |
Body image (self-identified) |
Gender (self-identified) |
Puberty staging |
Privacy |
Anxiety (self-identified) |
Columbia Impairment Scale (self-identified) |
Bullying (self-identified) |
Depression (self-identified) |
School Performance |
Eating habits/patterns |
Smoke exposure |
Child health/medical conditions |
Medications around birth |
Coughing episodes |
Wheeze |
Medications |
Allergy skin testing |
Atopic dermatitis/eczema/rhinitis |
Antibiotics in first year of life |
Introduction of milk and solids |
Weight for age trajectories birth to 5 years |
Lung function (spirometry) |
Asthma diagnosis (methacholine challenge) |
Food allergy |
Breastfeeding |
Download list of variables in Excel:
For an overview of environmental factors assessed in the CHILD Study, see Takaro et al (Journal of Exposure Science and Environmental Epidemiology, Mar 2015).
For an overview of study progress and data collection to age 8, see From Fetus to Eight: the CHILD Cohort Study (American Journal of Epidemiology, Oct 2024).
Download list of variables in Excel: Key variables – CHILD Cohort Study